Early this year, MuckRock was invited to participate in the JournalismAI Collab, working with other news organizations across the Americas to export, test, and develop new ways to apply AI and machine learning to investigative challenges. We partnered with CLIP, Ojo Público, and La Nación to get further feedback and continue developing Sidekick, and these pieces share the results of this collaboration. Read the other pieces, available in both English and Spanish, on the DockIns project page.
Ever get a pile of documents and want to start quickly honing in on a certain segment of material? Wish you had a little help pulling out just contracts, or maybe police reports that detail a certain type of encounter, or be able to quickly divvy up supportive and negative letters to a politician about a key issue?
With MuckRock’s DocumentCloud platform, that’s a challenge we know all too well — we now host over 7,782,977 documents comprising 130,233,118 pages of primary source materials, which is a lot of reading.
As part of the 2021 JournalismAI Collab Project DockIns and in partnership with La Nacion, CLIP, and Ojo Público we’ve developed SideKick, a machine learning platform baked right into DocumentCloud designed for quickly and efficiently training new models based right within the DocumentCloud platform itself.
This work builds directly off pioneering interface and modelling research by Prof. Eli T. Brown and the Laboratory for Interactive Human-Computer Analytics. It also extends MuckRock’s prior work supported by the Ethics and Governance in AI Initiative and the Knight Foundation, and we’re excited to roll these technologies out in preview as we work to continue gather feedback and explore new ways to help newsrooms, researchers, and civic technologists stay on top of an ever-increasing flow of documents and data.
We were particularly interested in supporting our partners efforts to analyze and monitor regularly released document sets, such as congressional question-and-answer sets released in Argentina and bulk-released government contracts.
How SideKick works
SideKick is designed to help you categorize and identify documents among large collections you have on DocumentCloud. Interesting can be defined however you like - even in multiple ways for a single collection, if there are multiple topics you are interested in.
You select a tag, start reading documents, and marking them as being relevant or not for that tag. Once you have marked some number of documents, you can run SideKick, and it will score all unmarked documents for how likely it believes they are to be of that category, based on the documents you already marked. Hopefully this pushes the most relevant documents to the top for your discovery. As you continue reading more documents you can tag them as well, occasionally re-running SideKick so that it can improve its scores as you provide more data.
How to Start
SideKick does not have a dedicated UI yet - all interaction is currently driven programmatically via the API. I have developed a set of example scripts, which we will use for this guide. Feel free to adapt these scripts to the specific needs of your project, and we’d love to hear about other scripts and use cases you build out! You will need to install the Python DocumentCloud library, which is a great starting point for any DocumentCloud work done in Python.
Create a project
The first step is to create a project on DocumentCloud which will be used for SideKick. Start by clicking on the New Project button in the left sidebar.
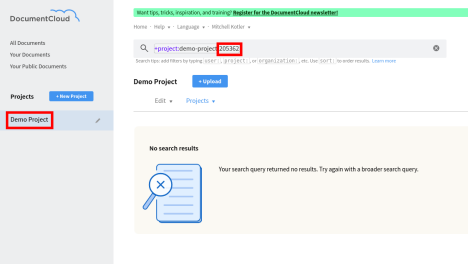
Fill in a name and optionally a description for the project and click create. The new project will appear on the left sidebar. Click on the project name and note the project ID for use in the next section. The project ID will be the number after the last dash in the search bar.
Configure client variables
Now, in client.py from this gist, you will need to change some of the values from the examples.
- USERNAME - set to your DocumentCloud username
- PASSWORD - this is set via an environment variable. This can be set via export
- DC_PASSWORD=<password> for the shell session, or by prepending it per command, as in
- DC_PASSWORD=<password> python script.py
- PROJECT_ID - set to the numeric project ID as noted in the previous step
- TAG_NAME - The tag you would like to use to mark document categories within SideKick.
Upload Documents
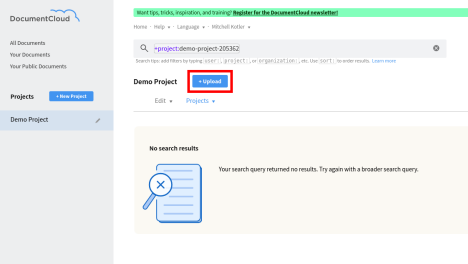
Go back to DocumentCloud in your browser. You should still be in the project you created for SideKick. You now want to upload your documents. Click on the upload button, select your files, and click on begin upload. Note that your project must contain over 300 unique words for SideKick to have enough data to properly initialize - make sure you upload at least a few documents of a substantial length to properly test.
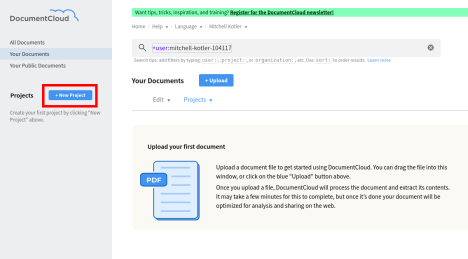
Initialize SideKick
Now we will initialize SideKick for our project. Run SideKick.py. It will initialize SideKick and wait for it to be ready before finishing.
This calls a POST request on https://api.documentcloud.org/projects/{PROJECT_ID}/sidekick/ , which begins to initialize SideKick on your project. It then calls a GET request on this same URL, until the status has changed from pending to success , which means that it has finished initializing. This may take a few minutes.
Note: If you add or remove documents from the project, you will need to re-run this step.
Label Documents
You now need to label some of the documents. You must have at least one positive document that matches the label, and we recommend negative examples, although they are not technically required. The more you label, the more accurate it will be in finding other interesting documents. You will be using the tag name you set in clients.py
First select the documents you would like to define a category for:
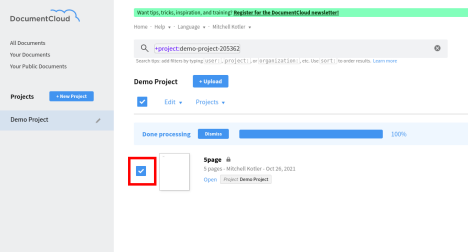
Then go to the edit menu, and select Edit Document Data.
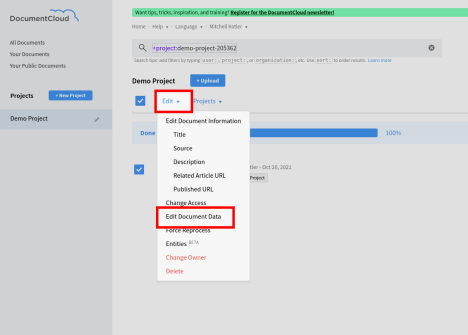
Then select Key/Value from the drop down, enter your tag from clients.py as the key, and enter true as the value. Click on the Add button, then click on the Done button.
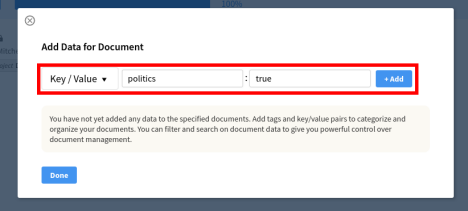
You may repeat this process to add more documents as examples of the category, or you may repeat it, replacing true with false as the value to mark documents as being not part of that category.
Run learning algorithm
You can now run the learning algorithm in order for SideKick to score all of the documents which you have not explicitly marked in the last step. This is done through the API, by calling learn.py from this script. This will again run and check the status until it is done processing.
This calls a POST request on https://api.documentcloud.org/projects/{PROJECT_ID}/SideKick/learn/ with a body of tagname set to your specified tag name. It then calls a GET request on https://api.documentcloud.org/projects/{PROJECT_ID}/SideKick/ until the status has changed from pending.
Analyze the results
Now you can refresh and see the scores assigned by SideKick. The score is a number between -1 and 1, with closer to 1 being deemed more likely to be within the category.
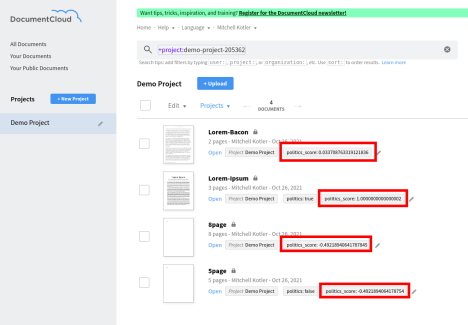
If you have a data set where you know which documents are part of a given category, you can compare the scores to see how SideKick did. If you do not know the answers, you can start looking at some of the documents SideKick scored highly, mark them as definitively in or out of the set, and then re-run the learning step to get updated scores. You do not need to re-initialize SideKick each time, you can just tag more documents and re-run the learning step, which should be relatively quick. You only need to re-initialize SideKick if you add or remove documents to the project.
If you give SideKick a try — or you’re interested in putting it to work on a large document set you have — we’d love to hear from you! Ping us at michael@muckrock.com or slide into the MuckRock FOIA Slack and let us know how it goes.
This project is part of the 2021 JournalismAI Collab Challenges, a global initiative that brings together media organizations to explore innovative solutions to improve journalism via the use of AI technologies.
It was developed as part of the Americas cohort of the Collab Challenges that focused on “How might we use AI technologies to innovate newsgathering and investigative reporting techniques?” with the support of the Knight Lab at Northwestern University.
JournalismAI is a project of Polis – the journalism think-tank at the London School of Economics and Political Science – and it’s sponsored by the Google News Initiative. If you want to know more about the Collab Challenges and other JournalismAI activities, sign up for the newsletter or get in touch with the team via hello@journalismai.info.
Header image via Shutterstock under commercial license.