Early this year, MuckRock was invited to participate in the JournalismAI Collab, working with other news organizations across the Americas to export, test, and develop new ways to apply AI and machine learning to investigative challenges. We partnered with CLIP, Ojo Público, and La Nación to get further feedback and continue developing Sidekick, and these pieces share the results of this collaboration. Read the other pieces, available in both English and Spanish, on the DockIns project page.
In the last six months of our Journalism AI collaboration we experimented with different tools and techniques in order to build our platform that helps investigative reporters understand and process unstructured documents to get useful insights.
Unfortunately, we haven’t yet finished develop a tool that combines those techniques under one end-user interface.
That’s why we put together some feature requests — both to DocumentCloud’s existing functionality as well as to additional tools and interfaces — that will make it easier to upload, process and get insights from a set of documents.
Here, we present the machine learning workflow we imagined:
- Tagging DocumentCloud documents during the upload process
- Exporting a Named Entity Recognition word cloud per project or document
- Tagging- Processing - improving loop
- Getting insights
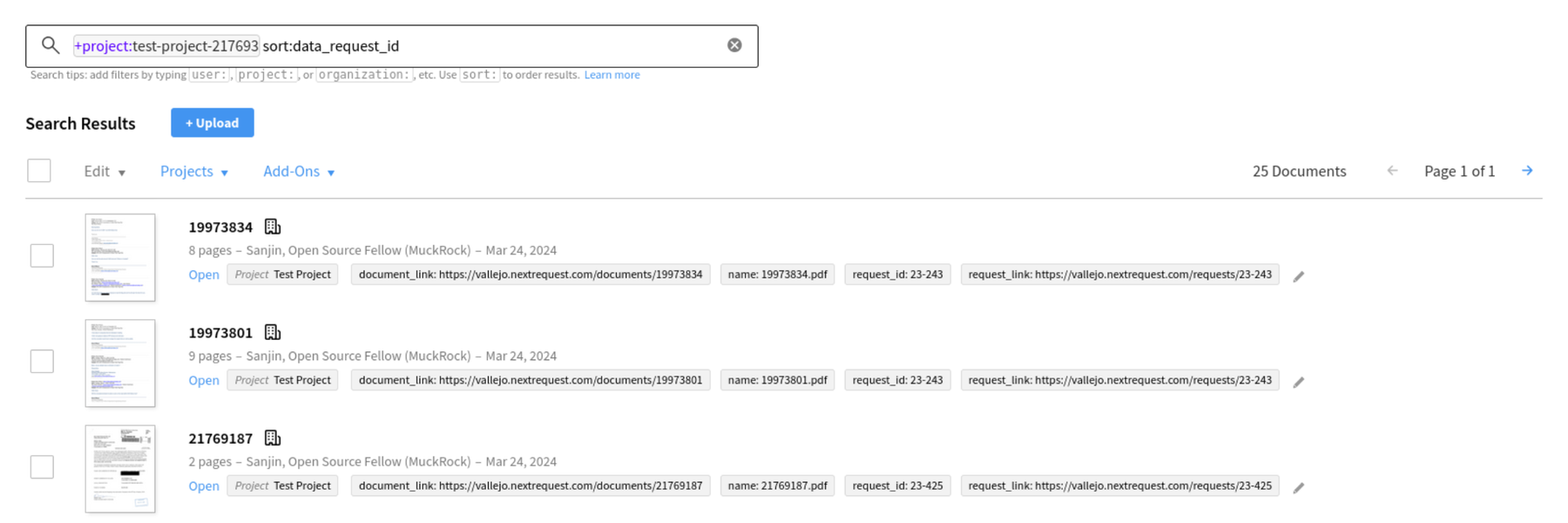
1. Tagging DocumentCloud documents during the upload process
Uploading a new document set will offer an option to associate and inherit or apply from the preloaded and pre-tagged document set the learned entities and tag/keywords.
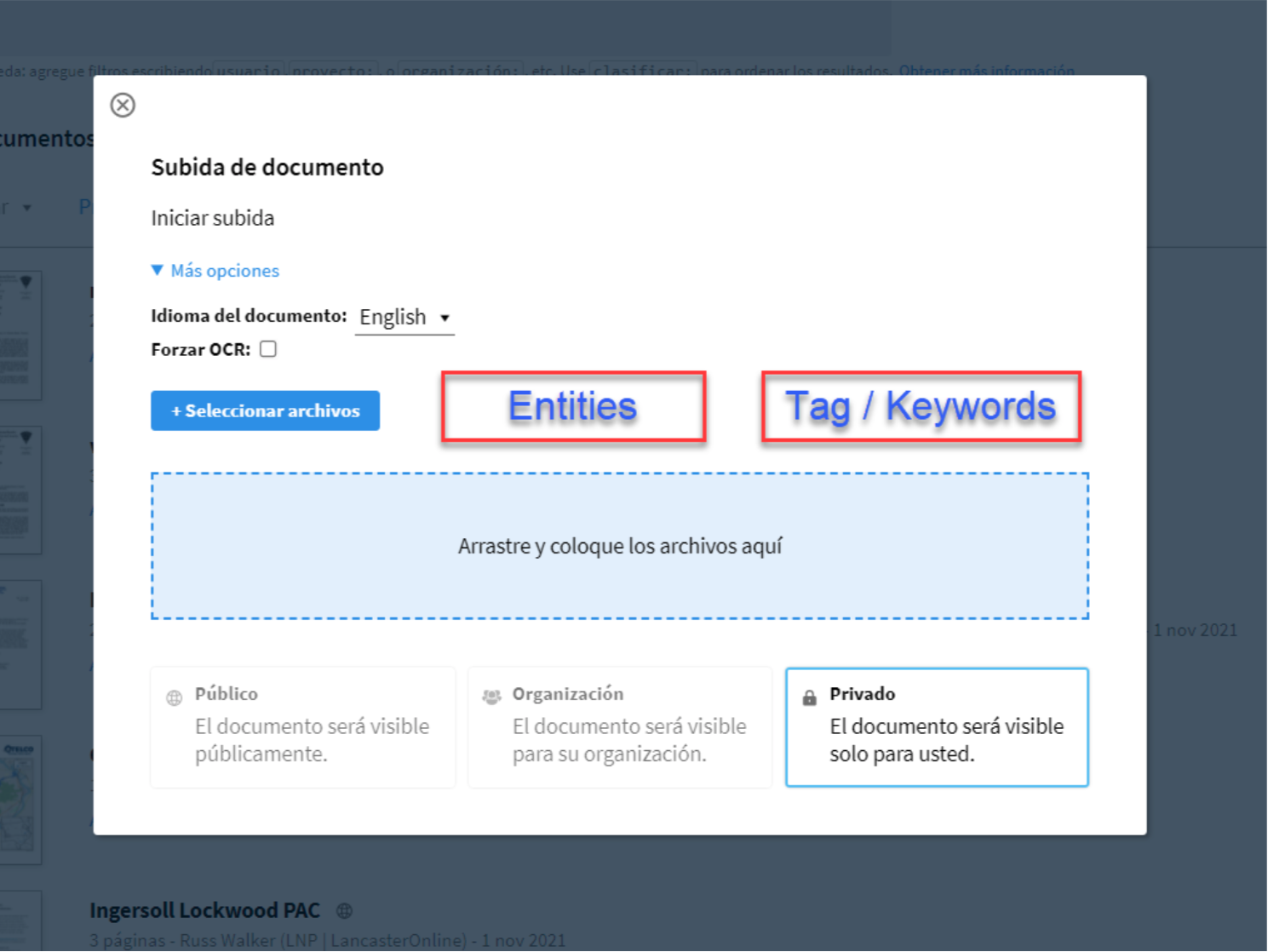
2. Custom Named Entity Recognition libraries and exportable wordclouds per project or document
Documentcloud already has an entity extraction tool based in Google Cloud API. In the Collab we also experimented with SpaCy, a Named Entity Recogntion library, and its EntityRuler, a pipeline which allows feed the entity model with a customized dictionary to boost accuracy based on a given set of documents within a particular domain.
As a result Dockins will provide an output with different wordclouds per project or document.
Identifying entities and most and most frequent terms, the NER model will allow customized stop words and filters per type of entity (event, address, organization, and other types of entities).

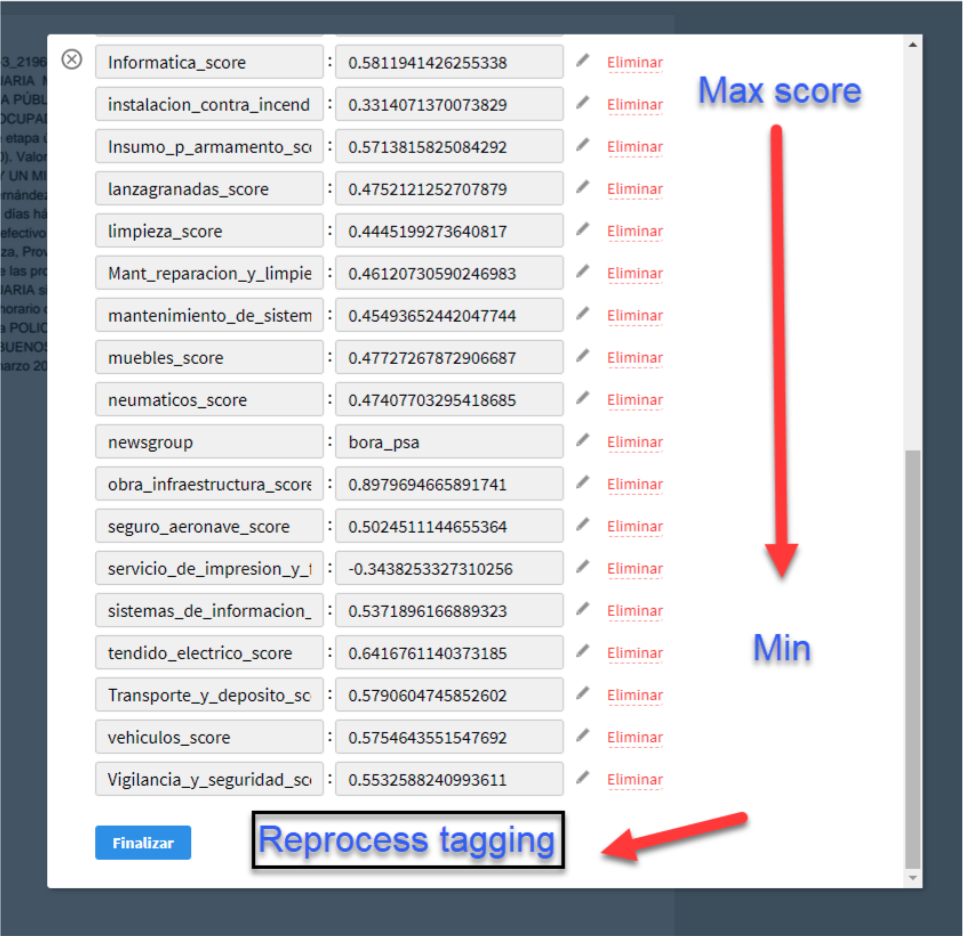
3. Improving the tagging → processing → training feedback loop
Based on the existing interface and our experience, we are proposing this improvements to the interface, which includes sorting by key value scores and a tool to re-process the model more quickly when additional information is added.
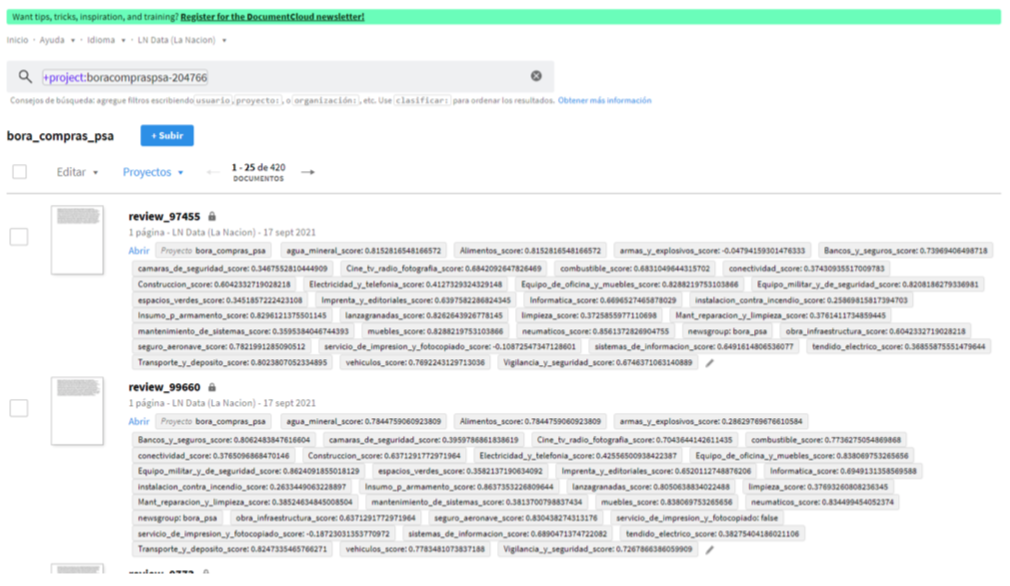
4. Getting insights
To make it easier to benefit from these insights, we also suggest making it easier to visualize and export this data on a project basis, such as by sorting documents within a project based on key value pair values or by offering new visualizations to quickly visualize which entities regularly pop up across documents.
This project is part of the 2021 JournalismAI Collab Challenges, a global initiative that brings together media organizations to explore innovative solutions to improve journalism via the use of AI technologies.
It was developed as part of the Americas cohort of the Collab Challenges that focused on “How might we use AI technologies to innovate newsgathering and investigative reporting techniques?” with the support of the Knight Lab at Northwestern University.
JournalismAI is a project of Polis – the journalism think-tank at the London School of Economics and Political Science – and it’s sponsored by the Google News Initiative. If you want to know more about the Collab Challenges and other JournalismAI activities, sign up for the newsletter or get in touch with the team via hello@journalismai.info.
Header image via Shutterstock under commercial license.