
A inicios de este año, MuckRock recibió la invitación para ser parte del JournalismAI Collab, y trabajar con organizaciones en las Américas para exportar, probar y desarrollar nuevas formas de aplicar inteligencia artificial y machine learning en algunos de los retos que enfrenta el periodismo de investigación. Nos asociamos con CLIP, Ojo Público, y La Nación para retroalimentarnos y continuar desarrollando Sidekick. En estos artículos compartimos los resultados de esta colaboración. Puedes leer todos los materiales en inglés y en español en la página del proyecto DockIns.
Como periodistas trabajando con documentos y bases de datos, nos encontramos con que la información más interesante se oculta en aquellos documentos que son largos, no estructurados o incompletos.
En particular , suele presentarse de este modo la información sobre contrataciones públicas, que contiene el background de los proveedores, y las condiciones y precios con las que compra el estado sus productos o servicios.
Cuando esta información se presenta en tres fuentes diferentes, incompletas y no estructuradas, aunque estén disponibles, no son accesibles, y por lo tanto tampoco transparentes.
Para resolver esto, cuatro organizaciones se unieron en un equipo del Journalism AI collab y experimentaron con diferentes herramientas de NLP y Aprendizaje Automático (ML) con la
idea de construir una solución que permita al periodismo de investigación comprender y procesar este tipo de documentos, extrayendo datos útiles y a su vez, organizando mejor los documentos. La plataforma se denominó: “DockIns”
El primer análisis concluyó que el reconocimiento de entidades nombradas (NER) podría servir para identificar los principales jugadores clave, nombres de personas, organizaciones, eventos o lugares. Por este motivo se testearon sobre los textos en español de contrataciones del Ministerio de Seguridad de la Nación, publicadas en el Boletín Oficial de la República Argentina, dos modelos: spaCy y DocumentCloud (que utiliza el Google Cloud NLP).
Para hacer esto se realizaron los siguientes pasos:
- Extraer los documentos y seleccionar una muestra de los documentos del Boletín Oficial de la República Argentina.
- Taguear manualmente esta muestra, utilizando Amazon Sagemaker.
- Aplicar el reconocimiento de entidades nombradas sobre la muestra utilizando SpaCy.
- Aplicar el reconocimiento de entidades nombradas sobre la muestra utilizando Document Cloud (Google Cloud Natural Language)
- Evaluar la performance de ambos modelos.
- Analizar y comparar los errores en ambos modelos.
Extraer los documentos y seleccionar una muestra de los documentos del Boletín Oficial de la República Argentina
El Boletín Oficial de la República Argentina (BORA) es el documento oficial donde se publica toda la legislación y otros actos de gobierno de los poderes del estado: poder ejecutivo, legislativo y judicial. En su tercera sección se publican las compras, contrataciones y licitaciones, de manera no estructurada y en texto.
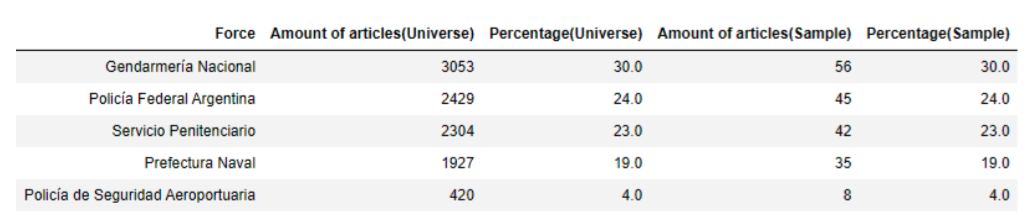
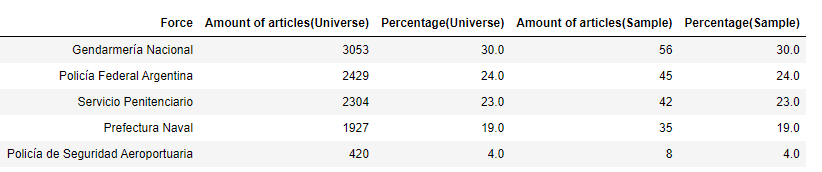
Para analizarlos se bajaron 10,133 documentos desde el 2014 hasta el 2021 que contiene información de contrataciones del Ministerio de Seguridad y cinco fuerzas policiales (Gendarmería Nacional, Policía Federal Argentina, Servicio Penitenciario, Prefectura Naval, y la Policía de Seguridad Aeroportuaria).
Luego se seleccionó una muestra proporcional a las diferentes categorías de cada fuerza con un nivel de confianza del 90% y 6% de margen de error.
Taguear manualmente la muestra, utilizando Amazon Sagemaker
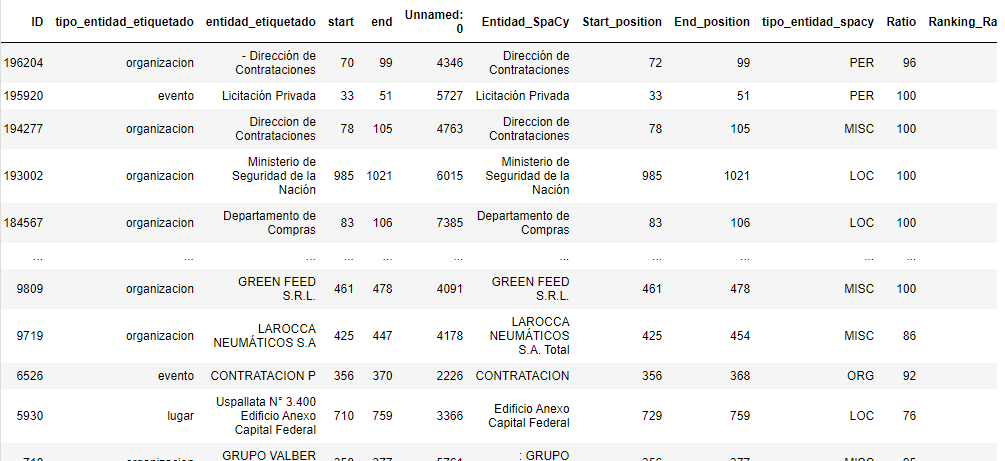
Para comparar la performance de los dos modelos de NER, necesitábamos identificar en la muestra cuales son las entidades de cada documento. Para este paso, realizamos un etiquetado manual de 186 documentos utilizando Amazon Sagemaker, un servicio de Amazon (AWS) que permite al usuario construir y entrenar modelos de aprendizaje automático (ML). Identificamos cinco etiquetas: Lugar, Organización, Evento , Personas y Otros.
Una vez que se completó esta tarea, obtuvimos un archivo en formato JSON , con el ID de documento, sus entidades, etiquetas, y posiciones (comienzo y fin).

Aplicar el reconocimiento de entidades nombradas sobre la muestra utilizando SpaCy.
Luego del tagueo manual, utilizamos SpaCy, una librería de código abierto para Procesamiento de Lenguaje Natural en Python. La libreria funciona en varios idiomas y contiene diferentes pipelines. En este caso trabajamos con spaCy 3.0 Spanish pipeline small para reconocer entidades en el mismo conjunto de documentos utilizados en el paso anterior.
También utilizamos la librería Pandas, para leer el CSV con la muestra y generar el output.
Los pasos para ejecutar esto son los siguientes:
- Instalar la librería Spacy: aquí las instrucciones para hacerlo.
- Seleccionar el pipeline a utilizar, y bajarlo: aquí se pueden encontrar todos los modelos y sus diferentes usos.
- Importar la librería spaCy y pandas a tu Jupyter notebook:

- Leer los datos que queremos utilizar (usando pandas):

- Ejecutar el NLP pipeline:
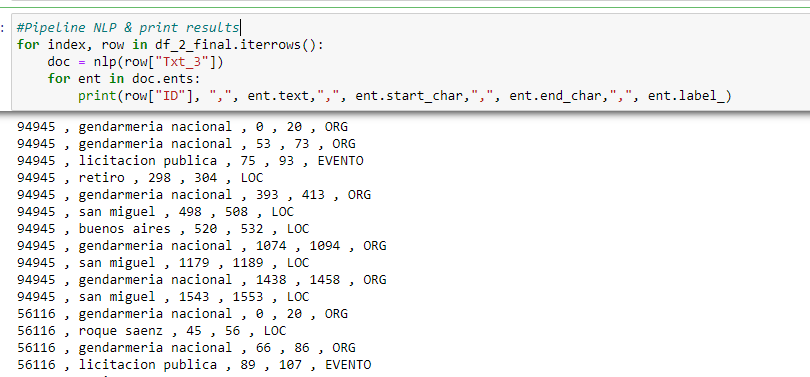
- Generar el Dataframe con los resultados del NLP : luego de ejecutar el pipeline generamos el dataframe con el ID del documento, las entidades y sus etiquetas y posiciones (inicio y fin)
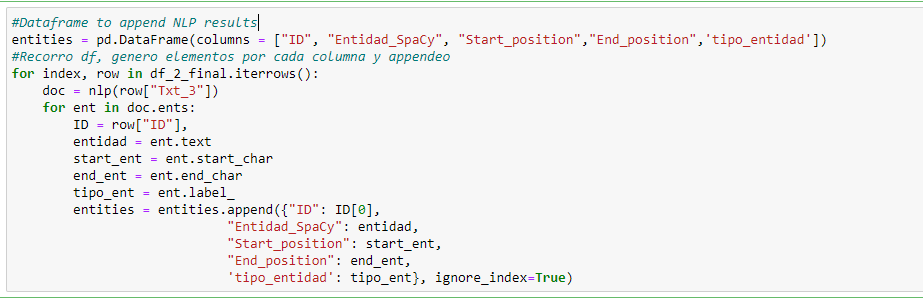
- Descargamos el dataframe como un archivo CSV:

Aplicar el reconocimiento de entidades nombradas sobre la muestra utilizando Document Cloud (Google Cloud Natural Language)
Completando nuestro testeo, utilizamos la API de DocumentCloud para extraer las entidades de la muestra de los documentos del Boletín Oficial de la República Argentina. Document Cloud utiliza a su vez, la API de Google Cloud Natural Language para reconocer y extraer las entidades de los documentos.
Para consultar la API de Documentcloud utilizando Python, primero instalamos la librería [python-documentcloud] . Una vez configurado el acceso a Documentcloud (usuario- password - ID de proyecto) procesamos los documentos uno por uno aplicando el requerimiento (request) a un endpoint específico de la API que respondió con las entidades de cada documento.
Nuevamente obtuvimos un archivo JSON como resultado de este proceso con el id de documento, las entidades, sus etiquetas y posiciones (inicio y fin).
Evaluando la performance de ambos modelos
Para poder evaluar la performance de los modelos, comparamos las entidades del etiquetado manual con las identificadas por spaCy , y luego con las detectadas por DocumentCloud.
La comparación se realiza a través de una Matriz de Confusión, que se manifiesta en una tabla y permite visualizar la performance de los algoritmos.
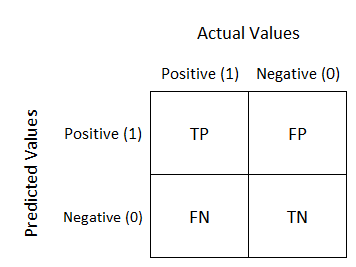
Para cada entidad del mismo documento, calculamos la distancia de Levenshtein un número que indica cuán diferentes son dos cadenas entre ellas. Para esta tarea utilizamos la librería en Python fuzzywuzzy .
Las entidades cuya distancia de Levenshtein es igual o mayor que 70 se consideraron como “verdaderas positivas” (true positives). Las entidades que fueron encontradas por el modelo y no fueron etiquetadas manualmente o las que tenían una distancia de Levenshtein menor que 70, se consideraron “falsos positivos”(false positives).
Las entidades que no fueron encontradas por el modelo pero que se encontraban etiquetadas manualmente o cuya distancia de Levenshtein fue menor que 70 se consideraron como “ falsos negativos”.
Luego calculamos Recall, Precisión, y la F1 Score, tres métricas utilizadas para evaluar la performance de modelos supervisados
-
Precisión: es el ratio de observaciones positivas predichas correctamente sobre el total de observaciones positivas predichas.
-
Recall (Alcance): es el ratio de observaciones positivamente predichas sobre todas las observaciones de la clase actual.
-
F1 score: es el promedio ponderado de Precisión y Recall. Este score tiene en cuenta los falsos positivos y los falsos negativos. Cuanto más se acerca a 1, mejor es la performance del modelo.
Aquí los resultados iniciales para SpaCy:
Precisión = 0.014
Recall = 0.095
F1score = 0.025
Aquí los resultados iniciales para DocumentCloud (Google Cloud API):
Precisión = 0.044
Recall = 0.138
F1score = 0.067
Análisis del error en ambos modelos
En ambos modelos encontramos que:
- Para algunas entidades que contenían más de una palabra pero fueron etiquetadas manualmente como una sola, ambas soluciones de reconocimiento de entidades nombradas (NER) las dividieron en partes. Por ejemplo , en los documentos que contenían “Gendarmería Nacional - Departamento de Compras”, el modelo tendía a reconocer dos entidades: “Gendarmería Nacional” por un lado y “Departamento de Compras” por otro lado.
- Los outputs difieren en los tipos de entidades. Ejemplo: las fechas y montos fueron reconocidas por el NER de Google pero no por SpaCy. Además, estos tipos de entidades no fueron considerados para el etiquetado manual, por lo tanto no se tomaron en cuenta para comparar ambos modelos.
- Los textos del Boletín Oficial son comunicaciones oficiales pero no son Press Releases, por lo tanto estos parecen oraciones aisladas pegadas en un párrafo. Este tipo de textos dificultan la comprensión de los modelos de NLP , dado que no siguen un patrón en común.
Al usar la herramienta de DocumentCloud, no pudimos customizar el modelo de Google para poder reconocer mejor las entidades en nuestra muestra. En el caso de spaCy, pudimos utilizar un componente del pipeline llamado Entity ruler que permite potenciar la precisión del modelo.
Para el EntityRuler, creamos un diccionario de entidades con sus tipos. Este, contiene departamentos y provincias de Argentina, todas las dependencias y departamentos del Ministerio de Seguridad, los tipos de eventos de licitaciones y contrataciones, entre otras.
Luego de implementar el EntityRuler, agregamos dos modificaciones para ayudar al NER de SpaCy: remover acentos y bajar todo el texto a minúsculas, dado que el modelo tiende a reconocer palabras con mayúsculas como entidades.
Estos cambios ayudaron al modelo a mejorar su score F1, de 0.025 a 0.078.
Como se mencionó anteriormente, el score F1 debe estar más cerca de 1 que de 0. Si bien el F1Score logrado no es muy prometedor, somos conscientes que uno de los problemas fue el etiquetado manual y los criterios de agrupación, que no fue detectado de ese modo por los modelos.
Creemos que se puede seguir investigando y reformular la estrategia de etiquetado para poder entender la performance de spaCy y Documentcloud en este tipo de documentos.
De todas maneras, los modelos NLP cambian su performance dependiendo del tipo de textos a los que son aplicados y es por esto que alentamos a la comunidad de ciencias de datos e Inteligencia Artificial para periodismo, a que sigan probando y utilizando estas en otros tipos de documentos y soluciones, y al hacerlo, compartan sus experiencias y aprendizajes.
This project is part of the 2021 JournalismAI Collab Challenges, a global initiative that brings together media organizations to explore innovative solutions to improve journalism via the use of AI technologies.
It was developed as part of the Americas cohort of the Collab Challenges that focused on “How might we use AI technologies to innovate newsgathering and investigative reporting techniques?” with the support of the Knight Lab at Northwestern University.
JournalismAI is a project of Polis – the journalism think-tank at the London School of Economics and Political Science – and it’s sponsored by the Google News Initiative. If you want to know more about the Collab Challenges and other JournalismAI activities, sign up for the newsletter or get in touch with the team via hello@journalismai.info.
Header image via Shutterstock under commercial license.



