
It’s been a while since we’ve published release notes, but we have a lot to share, including improvements to our crowdsourcing Assignments tool and a number of new DocumentCloud features.
And as we wrap up swapping the DocumentCloud Beta to be just the new DocumentCloud, we’re also shifting more time focusing on core MuckRock improvements, so if you have feedback, ideas, or feature requests, please let us know!.
For previous site improvements, check out all of MuckRock’s release notes, and if you’d like updates emailed to you — along with ways to help contribute to the site’s development yourself — subscribe to our developer newsletter here.
Assignments now supports ad-lib style text replacement
We forked Assignments, our crowdsourcing tool, to more quickly respond to some of the information gathering challenges presented by the COVID-19 pandemic, with the idea that offering more flexible ways to organize groups to collect and analyze information.
While Assignments was good for iterating over pages in a large document or parsing through batches of social media posts, we wanted to make it work for a wider range of tasks while retaining some of its basic ideas around flexibility and ease of use.
With support from an Aspen Tech Policy Hub COVID Challenge Grant and the John S. Knight Journalism Fellowships at Stanford University, we were able to make those feature improvements, and we’re glad to share that the functionality has now been ported over to the core Assignments tool.
You can upload a spreadsheet with custom columns, and then use those columns headers as template tags throughout the questions of an Assignment. A simple example:
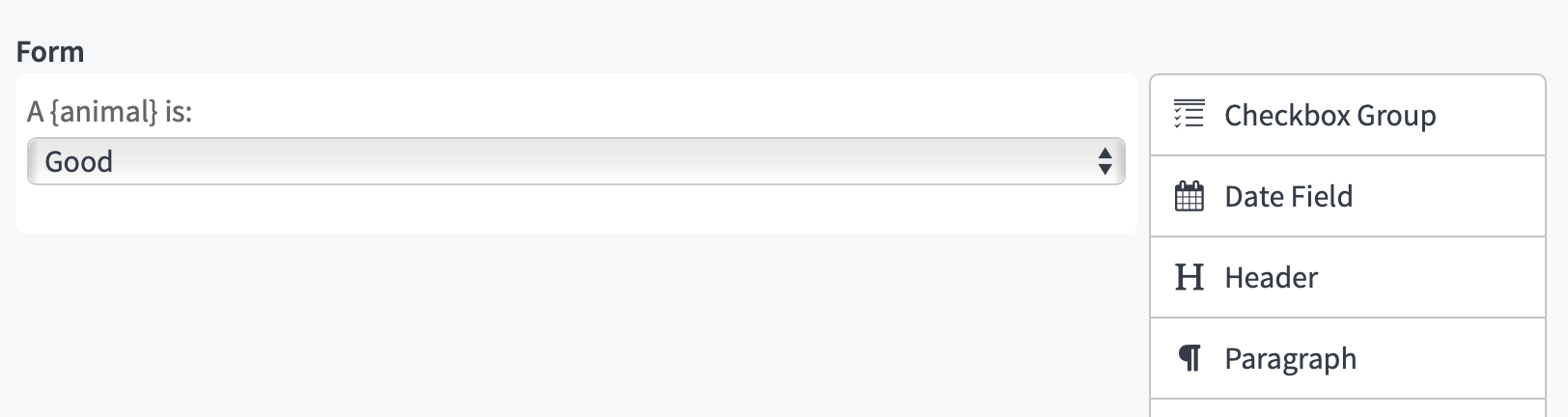
Then, when volunteers or colleagues go to the Assignments URL, they’re shown the data from a random row of that CSV inserted into the questions.
For example, one person viewing a page might be asked to denote the alignment of a cat …
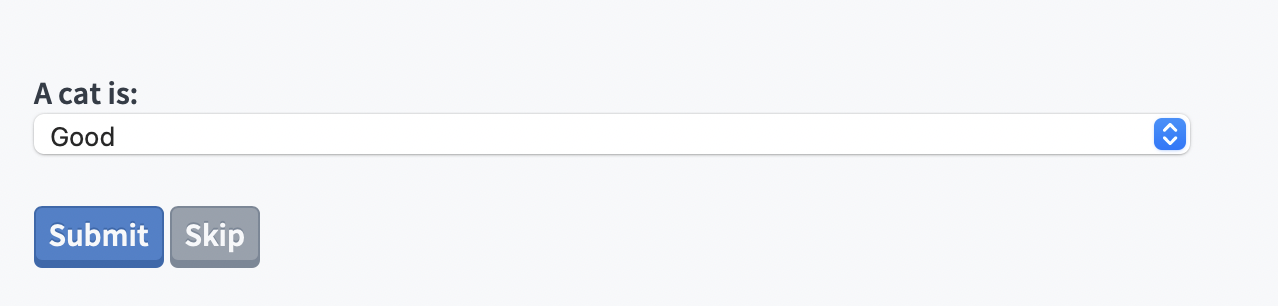
while the next is presented the same question about the squirrel …
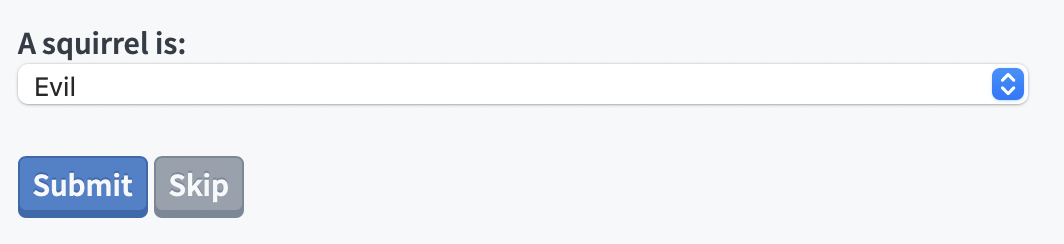
This makes it easy to set up complex task queues, and we’re excited to explore this approach’s potential in the coming months.
Sunsetting our Question and Answer forums
We’re big believers in community knowledge — it’s fundamental to how our platforms help better even the scales of requesters trying to understand the complex and often beguiling FOIA process. But we haven’t been able to dedicate many resources into moderating or updating our question and answer forum, and it began creating some confusion about where to turn for help, and we often wouldn’t see these queries in a timely manner.
So we’ve disabled creating new Question and Answer forum questions and answers, and plan to remove the section offline entirely at some point in the future. We do continue to offer real time community support through the MuckRock FOIA Slack.
DocumentCloud Updates: Scheduled publishing, easier collaboration, beta entity extraction
Over the past few months, we’ve been hard at work rolling out new features to DocumentCloud, and wanted to highlight some you might have missed:
-
DocumentCloud access for everyone — with a caveat: Now everyone with a MuckRock account can log in to DocumentCloud. While verification is still required to upload or publish documents, anyone can register for a free account to use most of DocumentCloud’s other functionality. If you’re a DocumentCloud user and want to collaborate with someone else, have them create a free account here, add the documents you want to share to a project, and then click the pencil icon by the project name, and then “Manage Collaborators.”
-
Scheduled Publishing: You can now schedule when private documents are made public, down to the minute. From the manager view, click “Edit” and then “Change Access,” or from the document editing view, click the current access level:
 You can then select “Schedule Publication” and choose a date and time to publish.
You can then select “Schedule Publication” and choose a date and time to publish.
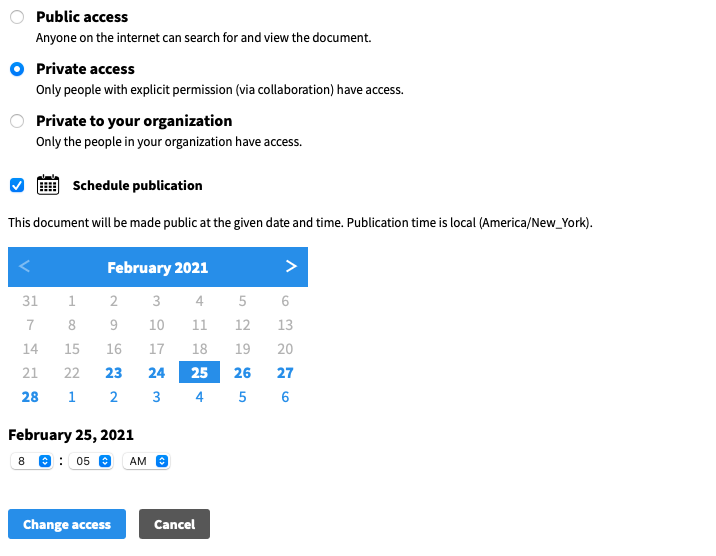
It even detects your local timezone so there’s less math to figure out!
- Entity Extraction: We’ve launched a first pass at more powerful entity extraction. From the manager view, select one document, click “Edit”, and then “Entities” to extract and view detected names, organizations, and more. We’re working on refining this functionality in the coming months and would love your feedback on how you’d like to use entities in your reporting.
Sunsetting DocumentCloud Legacy servers: What you need to know
We’ve migrated the last users from DocumentCloud’s legacy systems to our new server and are beginning the process of updating embeds to the new format. For most users, the impact will be minimal with no intervention required:
-
Starting in a week or two, old embeds — including document, project, notes, and page embeds — will swap from the old format to the new automatically. We’ll keep the same dimensions and style options, but the viewer will look slightly different.
-
A couple of weeks after that, we’ll swap beta.documentcloud.org in for DocumentCloud.org — no more having to remember the new URL. The legacy server will still be available for any troubleshooting and recovery needs. At this point, unauthenticated access to the legacy API will cease working except for the oEmbed endpoint, which will be forwarded to the new endpoint so that CMS integrations that rely on it should continue to work without change.
-
Two to four weeks after that, with physical backups made in case of emergency, we’ll decommission the old server.
Our team is working to spot check a number of embeds — if you have a particularly unique embed use case or other special integration, please reach out and we’ll add it to our list to monitor for any issues. We’re particularly interested in examples that use the legacy oEmbed endpoint to get embed codes so we can check implementations.
DocumentCloud API Users: If you have heavily customized the viewer or have DocumentCloud integration that relies on the API, we want to make it a smooth transition if needed. Our API documentation is here and the updated Python library is here.
Image via Wikimedia Commons




{kind=link}