
The MuckRock and DocumentCloud teams have made several platform upgrades and improvements, feature integrations and open source contributions over the last two months. Users now have the ability to edit titles of MuckRock requests, as well as new Add-Ons for entity extraction. We’ve also improved access to our DocumentCloud API and open sourced our data and analysis techniques for our editorial collaborations.
MuckRock improvements
-
MuckRock and Squarelet now run on Django 4.2.
-
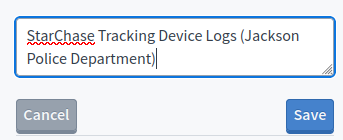
MuckRock public records requests now have editable titles.

- MuckRock user profiles now display a “pages released by records request” statistic telling you how many pages of documents your public records requests have released.

DocumentCloud improvements
-
DocumentCloud now runs on Django 4.2.
-
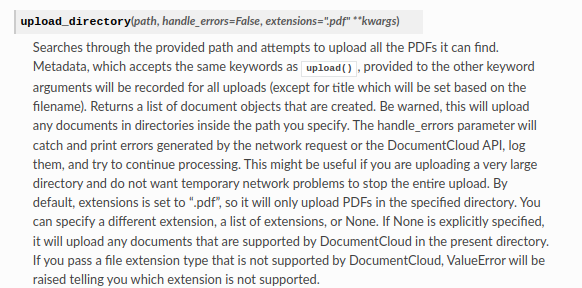
python-documentcloud 3.4.0 has been released. This updated version of the Python wrapper for the DocumentCloud API includes a rewrite of upload_directory() that now allows you to upload all supported file types using the method, not just PDFs.
DocumentCloud Add-On improvements
-
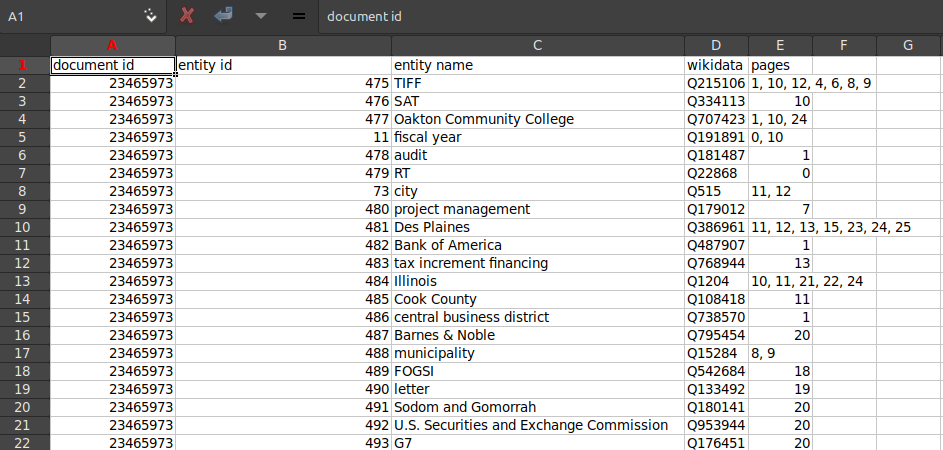
The DocumentCloud team is happy to share three new Add-Ons related to entity extraction. The first, Google Cloud Entity Extractor, uses Google Cloud’s natural language API to extract entities from your document set. From there, you can export your extracted entities to a CSV using Entity Export or export an HTML view of your exported entities using Entity Export HTML.

-
Bulk Tag Add-On allows you to add regular tags or key/value pairs to more than 25 documents at a time.
-
The Import Documents Add-On, which allows you to upload files from Google Drive, Dropbox, WeTransfer, and Mediafire now supports uploads of all 70 supported file types.
Open source contributions
-
Data, code, and analysis for MuckRock’s recent story on wildfire smoke and analyzing exceptional wildfire events is now public on GitHub.
-
The MuckRock team’s Atomic Fallout collaboration includes a timeline map of radiation in the St. Louis region. The code for this timeline map is now public on GitHub.
-
savepagenow, originally developed by Ben Welsh, is a simple Python wrapper and command line interface for the Internet Archive’s SavePageNow feature. The library now has the ability to do authenticated requests thanks to contributions by the DocumentCloud team. Unauthenticated requests are only allowed 4 captures per minute, but authenticated requests are allowed 12 per minute.
Image via Wikimedia Commons



{kind=link}