The DocumentCloud team is pleased to introduce a new way to upload responsive documents from MuckRock requests directly to your own DocumentCloud account, three powerful new OCR tools and several enhancements to our Python wrapper for the DocumentCloud API. These updates will help you upload documents more efficiently and provide better error tracking.
New MuckRock Feature
MuckRock users who receive a responsive document from a public records request can now upload the responsive document directly to their own DocumentCloud from within the MuckRock request as long as they are also verified to upload documents on DocumentCloud.
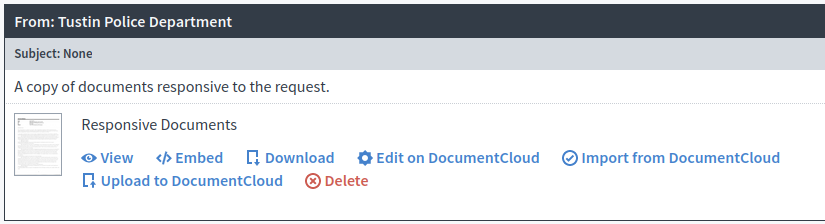
Clicking on the button creates a banner at the top of the MuckRock request alerting you that it will be uploaded to your DocumentCloud account shortly.
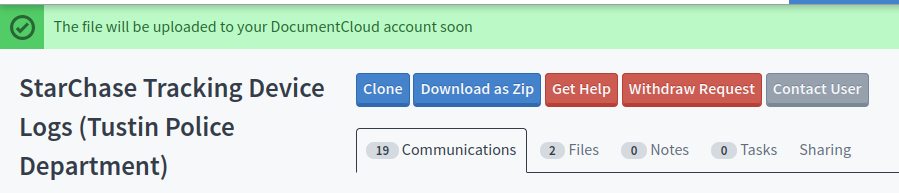
The document(s) will then appear in your DocumentCloud account under a “MuckRock Imports” project and will include metadata about the request it belongs to attached to the document.
New Add-Ons
Both the Azure Document Intelligence and Google Cloud Vision Add-Ons are premium Add-Ons that require AI credits to run. To learn more about AI credits, read our DocumentCloud premium page. The docTR Add-On is free for all DocumentCloud users.
Below is a sample illustrating the OCR quality differences between Google Cloud Vision OCR and Tesseract for a document from the January 6 Commission project hosted by DocumentCloud.
Results of the OCR using Tesseract:
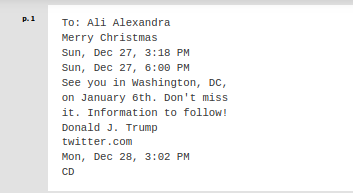
Results of the OCR using the Google Cloud Vision OCR Add-On:
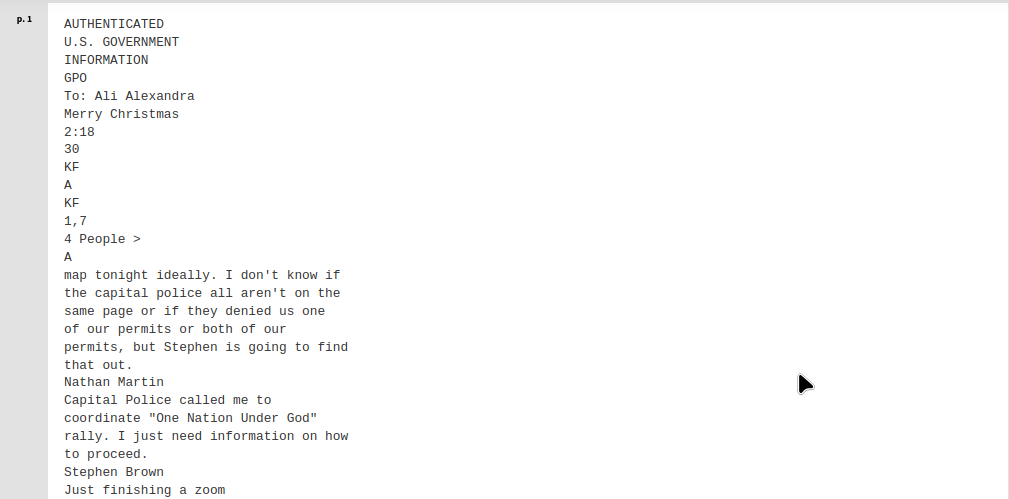
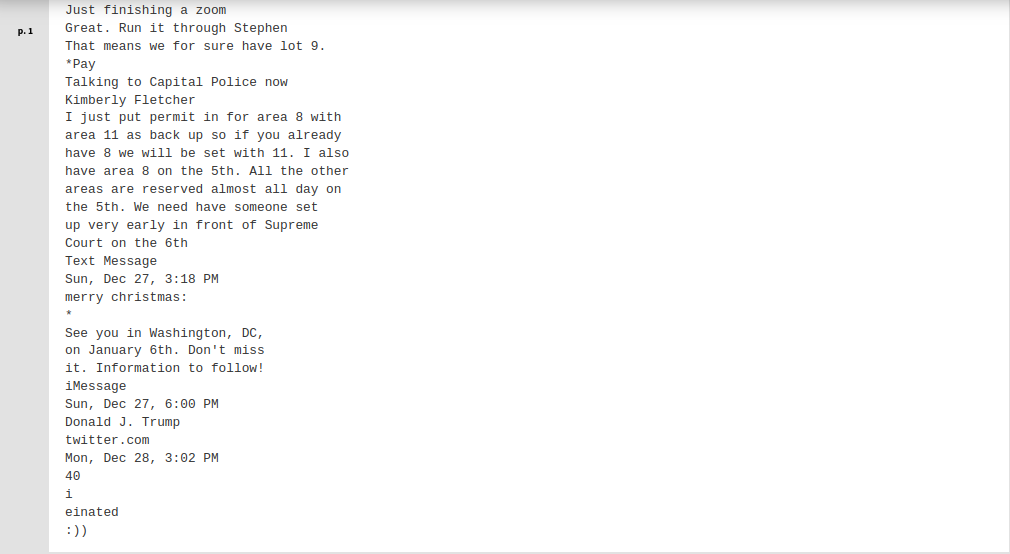 You can observe that entire sections of the text conversation were not recognized by Tesseract but were captured by Google Cloud Vision.
You can observe that entire sections of the text conversation were not recognized by Tesseract but were captured by Google Cloud Vision.
Azure Document Intelligence OCR
Below is a sample demonstrating OCR quality differences between Azure Document Intelligence and Tesseract for a document from the January 6 Commission project hosted by DocumentCloud.
Results of the OCR using Tesseract:
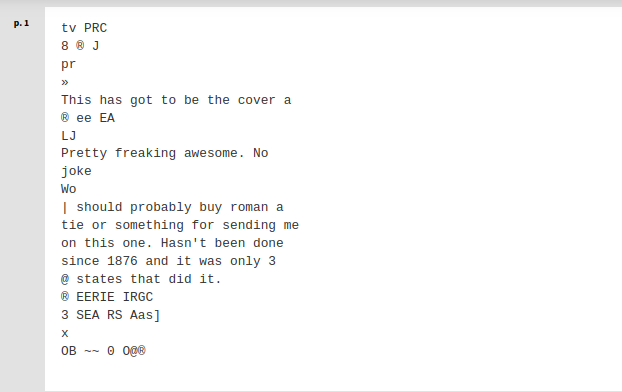
Results of the OCR using Azure Document Intelligence:
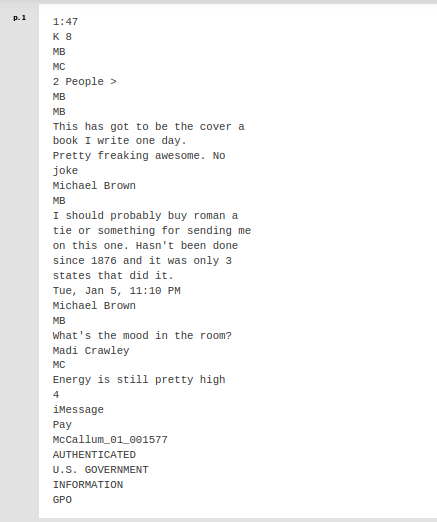
For those who are curious, here is Azure Document Intelligence’s performance on the same document that Google Cloud Vision tested against Tesseract.
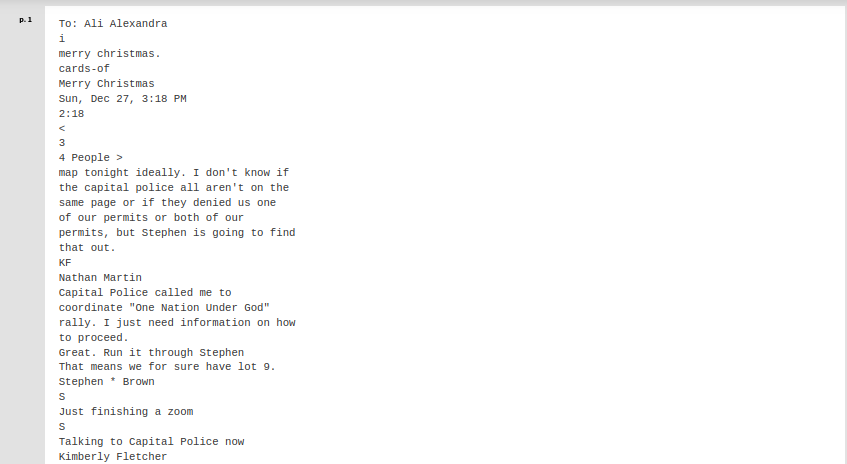

Both engines performed admirably.
The docTR OCR Add-On is free, open source and uses the machine learning-based docTR library to provide more accurate recall. Preliminary tests indicate that docTR provides much more accurate results than tesseract, DocumentCloud’s natively supported open source OCR engine, with the caveat that it does not support as many languages.
We can see a comparative view of Tesseract and docTR’s performance processing the following document.
Results of the OCR using Tesseract:
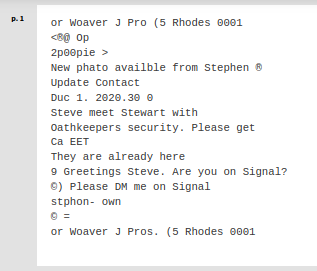
Results of the OCR using docTR:

We are currently conducting additional tests to compare Tesseract, docTR, Amazon Textract, Google Cloud Vision, and Azure Document Intelligence. We plan to release an article detailing our full findings soon. To stay updated, please subscribe to our weekly newsletter.
Python Wrapper Improvements
The Python wrapper for the DocumentCloud API has a new release
python-documentcloud 3.6.0.
The changes include two new methods:
-
get_errors() returns a list containing entries for each error on a document
-
upload_urls() allows you to provide a list of document URLs to upload to DocumentCloud. It will bulk upload the URLs 25 at a time. This method is useful if you intend to implement your own web scraper to automatically upload content to DocumentCloud
New Videos & Documentation Improvements
The team has produced a few new videos to assist users in navigating the new Add-Ons user interface, using tags and key/value pairs on DocumentCloud, backing up metadata of documents uploaded to DocumentCloud and detecting PII in their document sets.
Example queries are now available in our search documentation to make using DocumentCloud’s search system a bit easier. Our Add-Ons documentation now includes a section explaining how to check your AI credit balance and request a usage log.