
The only thing better than getting back documents after filing a public records request is getting back a lot of documents.
But as any reporter knows, government documents don’t usually arrive in a package with a bow and a handwritten note about the story the documents will eventually reveal. Instead, you get a stack of papers (or a digital stack of papers) without any apparent organization or roadmap for how you should dive in and start muckraking.
Where do you start? Before you can start combing through, sometimes you have to do the plumbing of investigative journalism. Plumbing means figuring out what types of documents you have, the details they contain and how you can extract the details to see the bigger picture. When you recognize a pattern of where to find this type of information over and over again, DocumentCloud’s Regex Extractor can help you pull it out and turn it into data. After that, the fun begins.
Pulling out basic pieces of information from documents and asking reporting questions about them is how a team of reporters working with MuckRock and New York Focus is making sense of over 27,000 pages of police disciplinary files. Read on to learn from our process and learn how to add structure to your trove of documents.
Find the needle in the haystack
Behind the Badge, a collaboration between MuckRock, New York Focus and a team of reporters, is organizing and releasing over 27,000 pages of previously unpublished police disciplinary files in New York state.
The documents have exposed homeless services officers in New York City who used excessive force, like one who broke the bone of a resident at a homeless shelter, a school officer who had a relationship with a student and continued to be rehired across the state — even police departments who claim they have no misconduct records at all.
Before our team could find trends and stories like these in the documents, we needed to understand what we were really looking at in those tens of thousands of pages. We developed a few basic questions:
-
What types of disciplinary files are in our documents? Are they letters to supervisors? Narrative reports?
-
Do we know the date of the incidents of misconduct? The troop or agency of the officer?
-
Is each document about a single officer?
-
Is each a single document with multiple pages or are there multiple documents rolled into one PDF?
To be able to find trends in repeat offenders, or departments with incidents of misconduct, we needed to be able to label the documents and count basic types of information. For the first story our team worked on, about homeless services officers in New York City, reporters did this by hand, reading each document and recording the information in a spreadsheet.
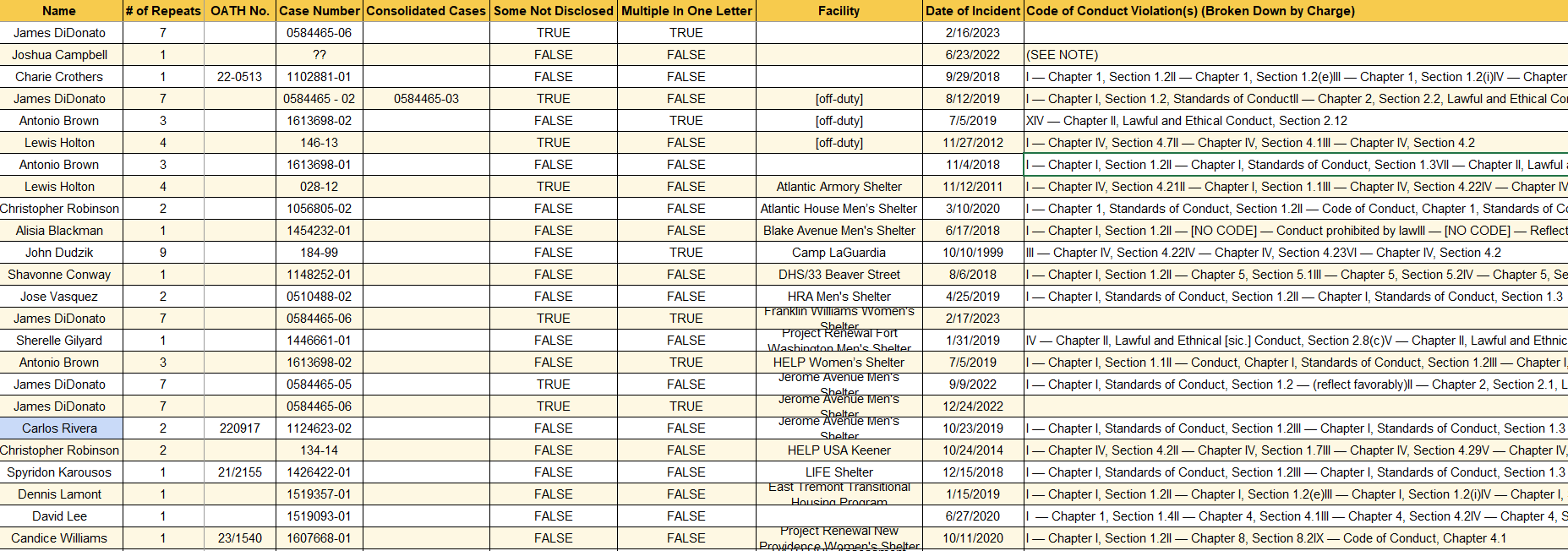
After that article, we began thinking about how we could record the same information for thousands more documents. We realized that at least some of the documents were standardized, like the disciplinary files from state police troops.
Standardized documents are a computer’s best friend, so we turned to DocumentCloud Add-Ons to extract information from the documents programmatically.
Turn text into data with regular expressions in DocumentCloud
Turning text into data sounds like a formidable task, one that could require complex software tools or even AI. It doesn’t have to be, and often shouldn’t be.
Our team knew that the disciplinary files from state troops had data we were looking for in nearly the same place on each document. Our goal was to order a computer to find that data on each document and pull it out, so that we could put it into a spreadsheet. Then we could begin to count things, like how many incidents of misconduct had happened in each troop, or how many times one officer had been reprimanded for different incidents.
Be sure your documents are digitized well
For a computer to read text from a document, it needs to know that the shapes on the screen are actually letters. This means that you have to make sure your documents are digitized accurately, so that the computer’s interpretations don’t mix up a V for a U.
The process of digitizing your document for a computer to read is called optical character recognition, or OCR. DocumentCloud uses a default OCR tool for when you upload documents, but also offers Add-Ons with more high-powered OCR capabilities for documents that are more tricky. Our team found that the Azure Document Intelligence Add-On rendered our documents most accurately.

Locate the text you want to extract
Once your computer can recognize the text on your documents, you can tell it which text to look for. This is especially helpful if that text has a format that repeats on documents. For example, dates often have two numbers for the month, a backward slash, two numbers for the day, a backward slash and four more numbers for the year. If you had no concept of dates, you’d probably be much less stressed than I am about deadlines, and I could still tell you where to find a date by saying that you can just look for these numbers and slashes.
When you give this type of command to a computer, it’s called a regular expression or “regex.” This sounds like math but is thankfully not. Really, you’re telling a computer to look for a date by finding by the characters or text around it, not looking for the exact date itself. Regular expressions use text and special characters to tell computers what format to look for information in.
Regular expression for matching the format of a date
\b(\d{1,2}[/-]\d{1,2}[/-]\d{2,4}|\d{4}[/-]\d{1,2}[/-]\d{1,2}|[A-Z][a-z]+ \d{1,2}, \d{4})\b
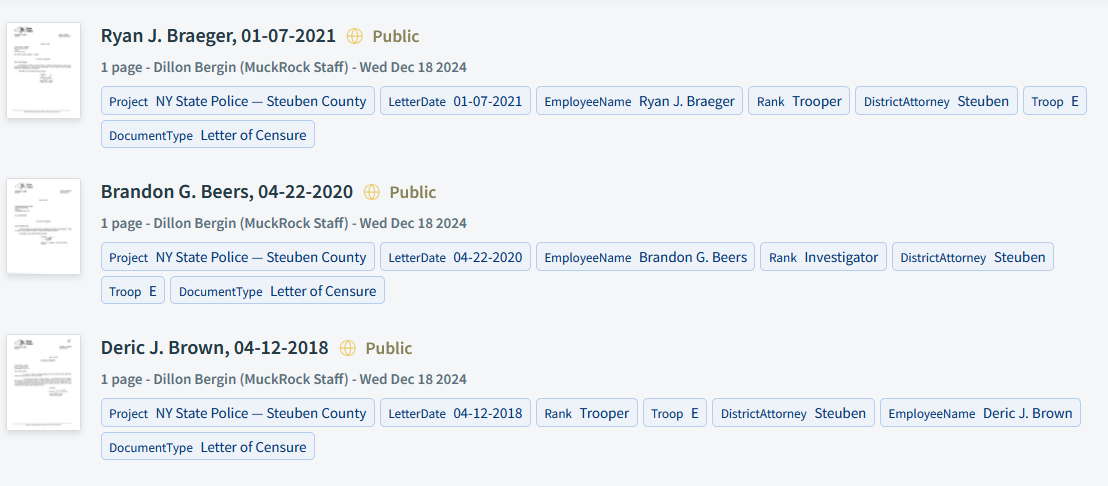
For our state police documents, we found many instances of formats we could pull out using regular expressions. We knew that the type of document we wanted to sort out from other documents was called a “letter of censure” and every relevant letter contained those words at the top. Each letter was also addressed to an employee in the format “Dear Trooper John Doe,” using the officer’s name and title. That was an easy one too. We could tell the computer to find the two words after “Dear…”. The letter also named the troop the officer was in, always listed after the word “Troop” at the top of the document.
Regular expression for matching the name and title of different state police employees
\b(?:Trooper|Investigator|Maintenance Assistant|Highway Safety Equipment Technician|Office Assistant|Clerk|Sergeant|General Mechanic|Communications Specialist|Senior Investigator|Sergeant S/C | Sergeant/SC|Security Services Assistant 1)\b\s+([A-Z][a-zA-Z]+(?:\s+[A-Z](?:\.|[a-zA-Z]+))?\s+[A-Z][a-zA-Z]+)
All we had to do was put these formats into regular expression language for a computer. You can get started generating a regular expression for your data by reading one of many great guides or watching a YouTube tutorial. Language models like ChatGPT are also great at helping with regular expressions, as are tools that check your regex so that you can see if it’s doing what you imagine it is.
Check your work by hand
As you probably know, computers are not perfect. And whether it is the result of a regex or an answer from a chatbot, you need to check your work.
Luckily, regular expressions are much more straightforward than AI, so checking your work is simple. We checked our work by labeling and sorting documents in small batches. This way, when the computer didn’t recognize the text we thought it should find, we could inspect the document and try to understand why it didn’t give us the result we had hoped.
We did this by using DocumentCloud’s Metadata Grabber Add-On, which pulls all our matched text from documents and puts it into a CSV that is easy to inspect. Doing this, we found cases of formats that we didn’t include in our regex originally, like someone with two first names, a middle initial and a last name. Instead of a match for these cases, we got nothing back. Once we looked back at the document, we were able to build this scenario into the regex.
What worked and what didn’t
What worked
- Using regex to identify simple and clear formats
- Using the Metadata Grabber to inspect our results, then using it again at the end of the process to check for unusual formats
- Checking work by hand in small batches so we could both maximize the time saved by pulling out this data programmatically and minimize the chance for programmatic errors
What didn’t work
- Documents that still returned weird characters, even with improved OCR. In these cases, we had to add data by hand
- Doing large batches of documents, which resulted into too many unusual scenarios that we hadn’t planned for, like people with two first names or documents without any detail about the troop the employee belonged to
Sorting more than just police disciplinary files
Using regular expressions with DocumentCloud’s Regex Extractor Add-On is a middle ground between relying on a computer or an algorithm to label documents for you, and doing all the labeling by hand. It requires a journalist’s thinking brain and structured text in documents, but it can speed up the process of labeling pieces of information that are repetitive. And though laying the groundwork for more complicated reporting and data analysis is not a glamorous job, it is usually the most important. With language models, computers can do more and more work for journalists. The journalists’ thinking brain is what makes any data extracted from documents useful. This is why regular expressions can be used not only for police disciplinary files, but for any structured document, like pollution complaints or financial reports.
Header image via Canva is not licensed for reuse without prior authorization. Illustration by Kelly Kauffman.