
The latest release of DocumentCloud introduces OCR injection, ensuring that OCR’d text from Textract or any Add-Ons is grafted into the underlying PDF, allowing for better local search functionality in downloaded files. This update ensures that documents OCR’d by any engine now have OCR text embedded in the PDFs for seamless local, offline searching. Additional improvements include updated DocumentCloud API documentation, bug fixes for page-level annotation access, and enhanced search result excerpts for easier text matching.
DocumentCloud
OCR Injection
Documents that are now OCR’d by Textract (built in) or any of our Add-Ons also get the OCR’d text grafted back into the underlying PDF during processing. Previously, only tesseract had this grafting functionality and the other OCR engines would only store the newly OCR’d text on DocumentCloud. Now, that OCR’d text gets added back into the underlying PDFs as well.
Before this update, the locally downloaded file would be missing the newly OCR’d text, which means searching from within the locally downloaded copy of the PDF would miss the OCR’d text, as seen below. The OCR’d text was still available for search from within DocumentCloud, but the underlying PDF was not updated.
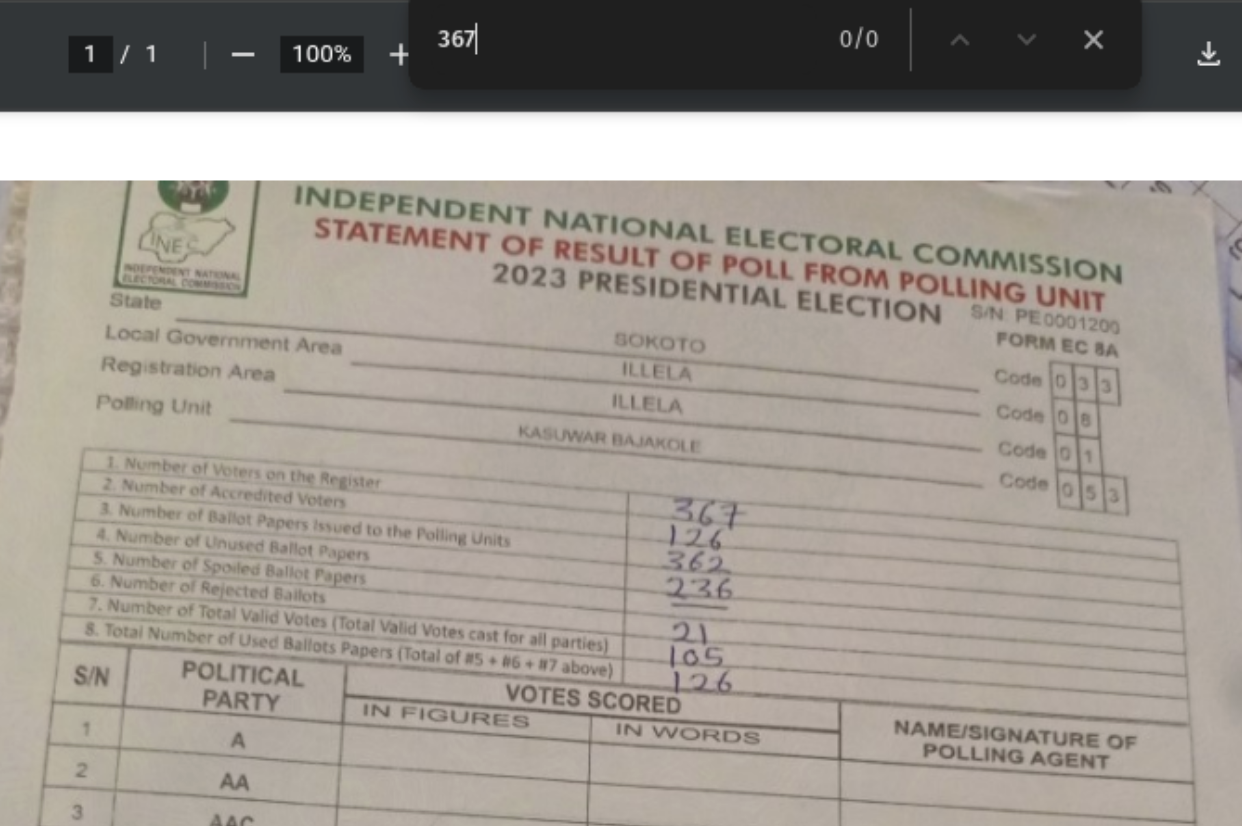
Now that OCR injection is applied on all models, the downloaded file can be searched locally with all of the newly OCR’d text added back into the original PDF.
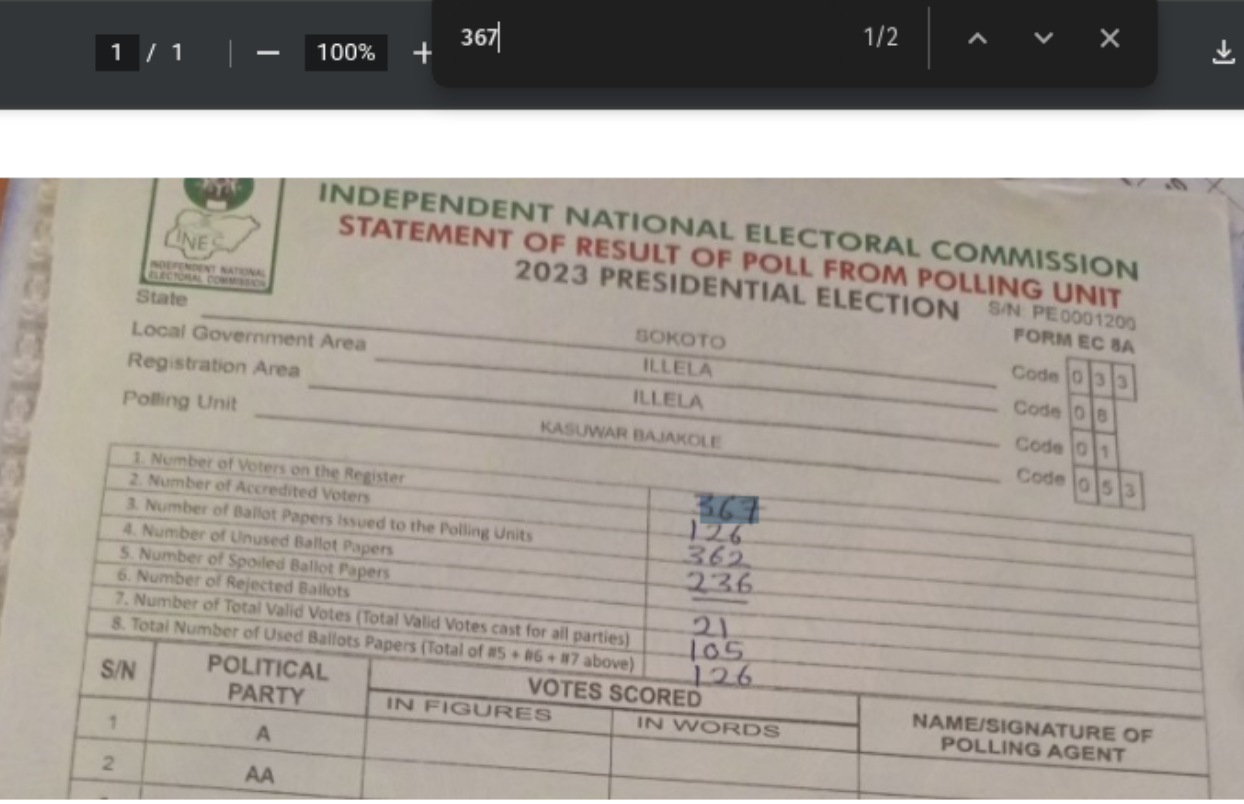
Other DocumentCloud Bug Fixes & Enhancements
The DocumentCloud API has new documentation, similar to the new MuckRock API v2 documentation, which uses drf-spectacular to auto-generate documentation when updates are made to the API and provides example requests and responses.
A bug when trying to edit the access level of page level annotation has been fixed.
DocumentCloud search results now show a larger text excerpt. This should make it easier to see matched tex within a document.



