
Public records, such as receipts and other financial documents, often hold the key to uncovering misuse of public funds. However, analyzing thousands of disorganized and poorly scanned documents can be a daunting task, especially when trying to detect patterns of inappropriate spending. Tools like DocumentCloud’s Empty Page Deleter, Regex Extractor, and OCR Add-Ons can streamline this process, while Push to IPFS/Filecoin and the Internet Archive Export Tool can back up copies to ensure the material stays available.
Read ahead to see how Fiquem Sabendo, a Brazilian transparency nonprofit, used DocumentCloud to reveal how a former president used his corporate card to pay for personal expenses—including yacht trips, luxury groceries, and vacations—and how you can use these tools to bolster your reporting too.
Imagine a president who, during a week of vacation from his official duties, uses public money to buy over 200 kilos of rump steak for his entourage, pays for fuel for yacht trips, and even rents rescue equipment for his leisure dives. It sounds unbelievable, but we proved this happened in Brazil by analyzing public documents.
In Brazil, authorities in the executive branch can access a corporate payment card to cover expenses during trips, small purchases, and classified expenses. Created in 2001 to fund minor and uncommon costs, this payment method has often been suspected of misuse and even faced a government investigation in 2008.
Use of the card is subject to the democratic principles of public administration outlined in Brazil’s Constitution (legality, impersonality, morality, publicity, and efficiency). But for over two decades and five presidential terms, the expenses of presidents and their teams have remained a well-kept secret.
Shine a light on hidden expenses
That was until Fiquem Sabendo, the nonprofit organization where we work, stepped in. Through Brazil’s Law on Access to Information (LAI), comparable to the United States’ FOIA, we disclosed this data for the first time. First, we obtained spreadsheets detailing corporate card expenses from 2002 to 2022, covering four presidential administrations: Lula, Dilma, Temer, and Bolsonaro. Then, we secured access to the corresponding receipts to investigate the nature of these expenses and verify the values listed in the spreadsheets.
In a collective effort, journalists and volunteers manually scanned thousands of receipts from Jair Bolsonaro’s presidency (2019-2023). We focused on Bolsonaro’s presidency as it was the most recent at the time, although the process is replicable for other administrations.
The spreadsheets had already given us an idea of how the former president used the corporate card (financing motorcycle rallies for supporters and spending thousands of reais at bakeries and perfume shops). But the scanned receipts gave us an unprecedented window into the details of these payments.
We had a few questions to answer:
-
What could the receipts reveal about inappropriate corporate card use that the spreadsheets hadn’t already shown?
-
Did the values in the receipts match those in the spreadsheets, thus verifying their reliability?
-
How could we use the receipts and accompanying justification reports to better equip our partner journalists for further investigations?
To answer these questions, we had to tackle a huge problem: The receipts had been stored in complete disarray in the Presidency’s archives. We faced 7,673 scanned pages that were barely legible and out of order. We needed help storing all these documents and then transforming them into readable and searchable files.
How we cleaned the documents using DocumentCloud
Using DocumentCloud, a tool developed by the MuckRock Foundation, we performed an initial cleanup of the PDFs containing all the scanned documents. This process first involved removing blank pages and correcting the orientation of every page in the document.
The Empty Page Deleter Add-On removed blank pages by detecting pages that did not contain text—it worked perfectly! Page rotation was done using the Document Rotator Add-On, which adjusted each page’s orientation based on its approximate tilt angle. By default, these Add-Ons generated new files with the changes, preserving the original document. It’s worth noting that this entire cleanup process was simple and required no programming skills.
First, our file looked like this:

After running the two Add-Ons, we had this:

We still needed to make each document easily searchable, which was a challenge because of how some of the pages were scanned. We tested three Optical Character Recognition (OCR) engines available on the DocumentCloud platform: Google Cloud Vision, Azure Document Intelligence, and Amazon Textract.
To evaluate the results, we used the plain text viewer on DocumentCloud, which allowed us to compare the content and formatting of the text after each OCR engine was applied. We found that Google Cloud Vision engine delivered the best results for our documents.
This step was crucial because it enabled much improved keyword searching. For example, for the following page in one document:

One page we received that included several ATM withdrawal receipts scanned to a single page.
The underlying text layer before we applied OCR wasn’t well formatted and contained a lot of garbled text.

After applying Google Cloud Vision OCR to the document, this is what the underlying text looked like for one receipt, as an example.

The OCR produced similarly great searchable text for other receipts and other types of documents which allowed for more accurate searching across the entire collection.
We didn’t stop at making the documents searchable. We strived to impose some order on our collection to make it even easier to find buried stories. Correlating purchase receipts, ATM withdrawal receipts, and expenditure justifications was no simple task. Often ATM withdrawals were several pages away from the expenditure reports for that receipt, with other receipts and reports in between them. Many times they weren’t even in the same document. To complicate matters further, multiple receipts were often scanned to a single page. Pages were out of order and weren’t numbered, so we didn’t know where receipts related to a specific expenditure report began or ended. To solve this problem, we used DocumentCloud’s Regex (Regular Expressions) Add-On to extract the government’s reference numbers and label them so we could order them. (A regular expression, or Regex, uses a specific set of rules to search for and find patterns in text, such as dates, email addresses, etc. If you’d like to read a brief introduction to regular expressions, check out this Regex lesson presented at NICAR.)
Using the Add-On allowed us to organize thousands of pages, using key/value pairs to group them into concrete projects such as:
From the spreadsheets previously made available by the government, we also knew that a significant amount of cash had been withdrawn using the cards during the Bolsonaro term. We compared withdrawal receipts with the expenditure spreadsheets to find the exact purchases and verify the spreadsheets’ accuracy.
Using the Regex Extractor Add-On, we extracted information from the OCR-generated text based on patterns written with regular expressions. After deduplicating the extracted data, we were able to create this spreadsheet that compiles all the receipts for 854 ATM withdrawals, information about who the cardholders were, and when these withdrawals were made.
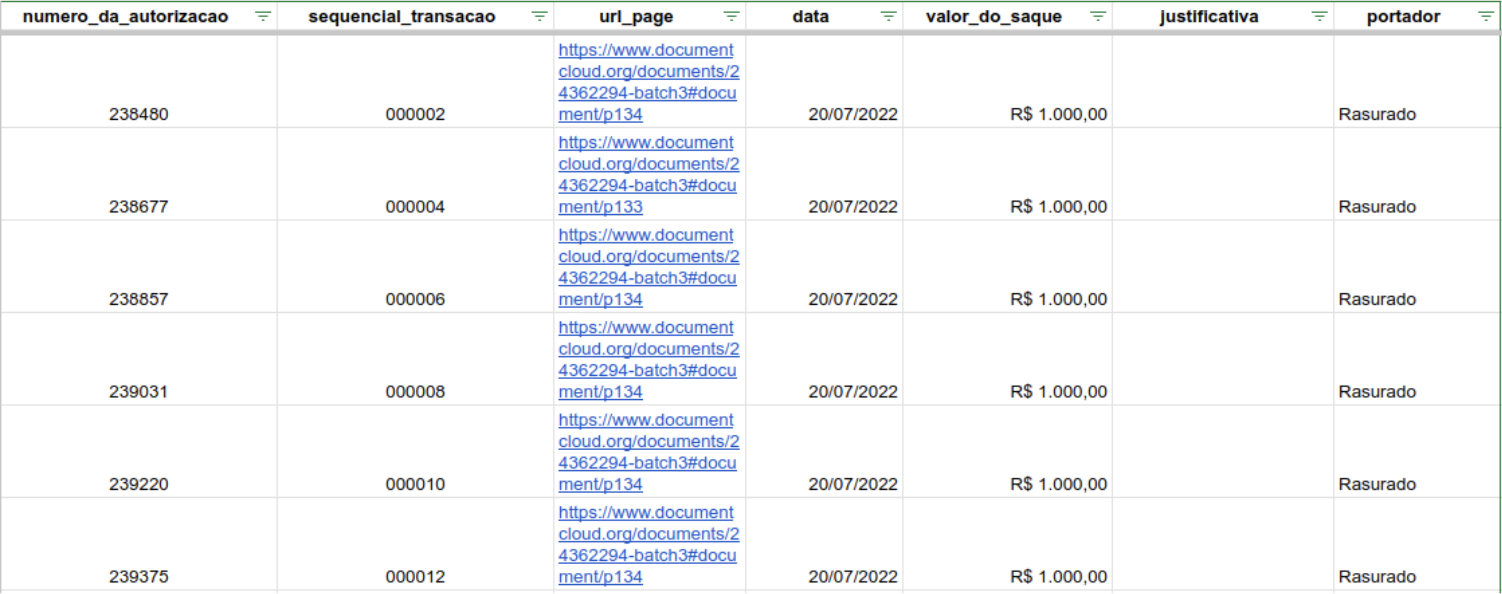
Finally, we needed to find leads for investigations in that bundle of receipts. Using our prior knowledge of the Bolsonaro government and with the help of the Regex Extractor Add-On, we began labelling documents with keywords like “picanha” (a type of steak), “jet ski,” “private jet,” as well as the names of beaches the former president enjoyed and individuals under investigation.
Whenever we found a suspicious expense, we checked the date in newspaper archives to confirm exactly where the president was and whether the spending made sense, given the card’s intended purposes.
That’s how we discovered that the former president used public money to cover personal expenses and those of his entire entourage during breaks from his presidency, burning thousands of reais on groceries and boat trips along the Brazilian coast. Can you believe that taxpayers funded the president’s Carnival?
This project would not have been possible without access to these primary source documents and it was important that they remained online and accessible. The materials were uploaded to the decentralized storage system IPFS as well as the Filecoin network via the Push to IPFS/Filecoin Add-On. These technologies work by seamlessly distributing copies of the material to multiple hosts, so if one provider removes the material, it’s still accessible at the same address. Additionally, Filecoin offers additional protections to ensure that files remain unmodified over time through its use of Content Identifiers instead of traditional URLs. You can access these documents on the project page or through an IPFS gateway.
What we learned for next time
As we worked on this investigation, we learned some lessons that might be useful for other journalists:
-
It’s difficult to uncover good stories in disorganized archives. We spent a few days cleaning, ordering, and categorizing files, and that was essential to our reporting process.
-
Using a quality OCR engine made a big difference in allowing us to search and uncover stories.
-
Prior knowledge of the subject can be crucial in finding good leads. If we hadn’t closely followed Bolsonaro’s presidency and already analyzed the spending spreadsheets, we wouldn’t have known to search for extravagant spending.
-
Cross-referencing and fact-checking expenses is vital to avoid mistakes during the reporting process, even with seemingly definitive documents like receipts. We leveraged newspaper archives, prior reports, public posts, and official records to confirm each expense.
Transforming hard-to-parse documents for investigations beyond this case
While Fiquem Sabendo’s investigation centered on exposing the misuse of public funds by a former president, the versatility of DocumentCloud’s tools extends far beyond this case. When faced with a large volume of poorly organized or hard-to-parse documents, Add-Ons can be a game changer in transforming them into actionable insights. For instance, reporters investigating police misconduct could use the Regex Extractor Add-On to extract key details from incident reports, while election transparency advocates might leverage our OCR tools to make handwritten election tabulations searchable and auditable.
Stay tuned for more stories on how investigative teams are using DocumentCloud Add-Ons to analyze public records, reveal hidden patterns, and hold those in power accountable.
Photo provided by Canva. Fiquem Sabendo’s reporting project and DocumentCloud technical development were supported by the Filecoin Foundation for the Decentralized Web. This article has been updated to include additional information on archiving and backing up documents.



